

Definitions of how I use the terms:
Data Governance: A system of oversight and guidance over the data, much like a government is a system of oversight and guidance for a country. The opposite of governance is anarchy, chaos, and entropy.
Data Democracy: A type of governance that ensures stakeholders are part of the governance.
Shift left: Assuming data flows from left to right, shift left represents a focus towards the origin.
Data Mesh: A decentralized data management strategy that treats data as a product, with domain-specific teams managing its quality, governance, and lifecycle.
Shift Left Data Democracy: From Access to Involvement
In the traditional view, data democracy was largely about democratizing access—ensuring that everyone across the organization could easily retrieve and analyze data. This was a crucial step forward, breaking down silos and making information more available than ever before. However, as we've evolved, so too has our understanding of what true data democracy entails.
Shift left data democracy represents a more profound change. It's not just about making data accessible post-factum; it's about involving a broader spectrum of roles in the very processes of data ingestion, processing, and management. This approach extends the principles of democracy to the entire data lifecycle, beginning with data ingestion.
It's a shift from mere consumption to participation, where access is just the beginning.
Data mesh is the driver
Just as the data mesh concept emerged to address the complexities of managing data in a distributed, domain-oriented environment, we now see a need for technology to evolve in parallel. The goal? To put data sources directly in the hands of the people who use them. This means giving teams the tools and autonomy to manage and process their data, ensuring governance and quality from the outset and throughout the data's lifecycle.
This shift left approach to data democracy aligns with the idea behind data mesh, recognizing that effective data management and governance are not centralized activities but distributed responsibilities. By involving more stakeholders from the very start of the data flows, we're not just democratizing access; we're democratizing the entire data flows.
Governance, from a power game, to a team sport; A brief history of how we got here
Building a data warehouse is a beaten path - but how to go from technical solution to organisation-wide application?
Building a data warehouse for reporting on some business processes is a good start, but in order to leverage that data we need a culture to do so and the skills to do it correctly.
While a centralised solution enables a skilled team to deliver results, these results are often inflexible without hands on help - so how can the organisation be expected to become data driven? The process of tracking a goal, creating hypotheses, starting an experiment and then tracking outcomes is much more complex than that of tracking a metric in a dashboard.
Cue, the move to democratic data access.
From Monarchy to Democracy: Data access for the people!
The move from a centralised system to a democratic system comes from the competitive use of data. In a centralised system where only management has access, data is used to keep track of goals. To enable people to use that data to do something about the goals, the user must have access and understanding of the data.
As with anything, the first step is obvious: Give people access - without it, there is no progress. However, once we do that, the reality rears its ugly head: Access is not enough!
Democratic access is great but as long as the data producers are not providing clean documented data , we don't have a democracy. Instead what we have is reality-adjusted communism - we all have plentiful access to the same black box or garbage that the big central team put in.
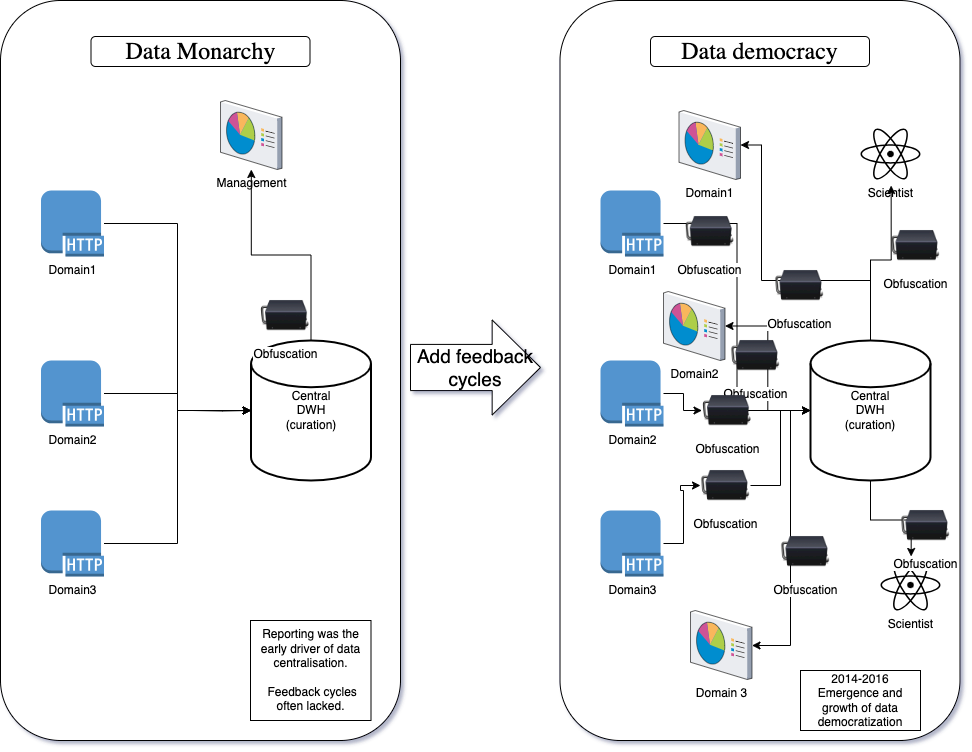
So, after democratizing data access, the next challenge was to answer the obvious question: So what does this data mean?
Turns out, the central team doesn't quite know either - it's rather the owner of the process we track, the data producer, that understands how the data they emit links to the real life process it tracks.
So how do we go from having data to understanding what it means?
From democratizing access to democratizing literacy though embedded analysts
One easy way to help teams understand the data is to give them an analyst resource. And what better than someone who knows their domain?
Cue the embedded analysts. These folks are crucial in bridging the gap between data capabilities and domain-specific needs. By positioning data experts within specific business units, organizations can ensure that the insights generated are highly relevant and immediately applicable to the domain's unique challenges and opportunities.
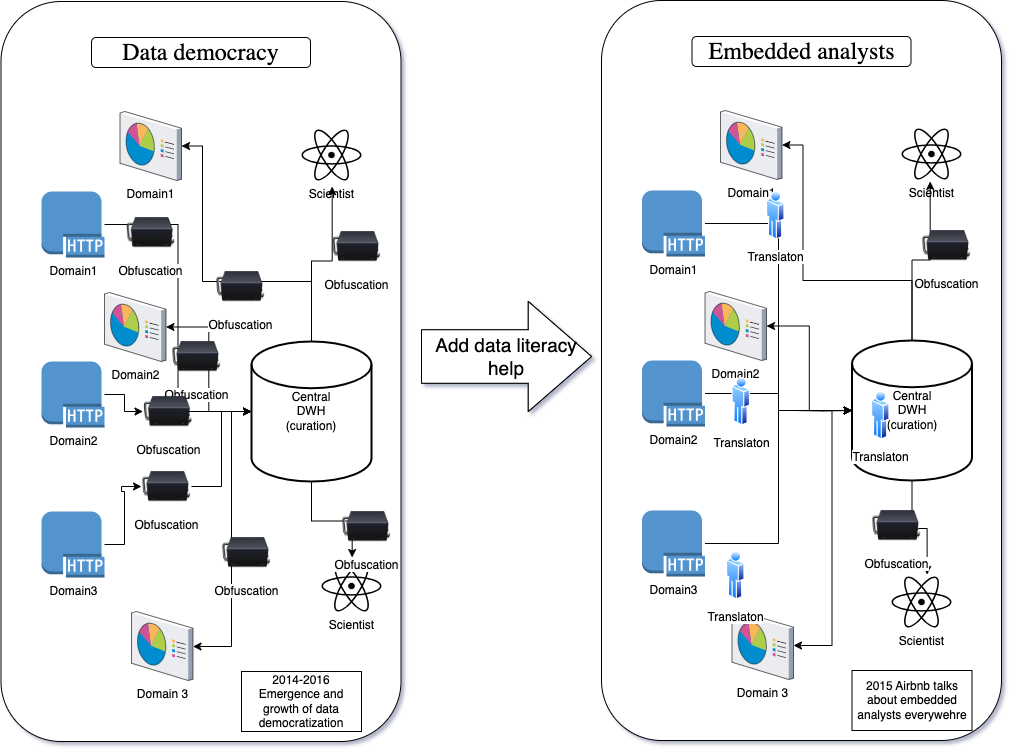
This placement helps in several key ways:
- Domain expertise meets data munging: Embedded analysts develop a deep understanding of the specific challenges and workflows of the business unit they are part of, which enables them to tailor data models and analytics strategies effectively.
- Data literacy: These analysts act as champions of data within their teams, educating and training non-data savvy members on data-driven decision-making processes. This upskills the team and increases the overall data literacy within the unit.
- Faster response times: Being close to the operational realities of the business unit, embedded analysts can deliver faster, more targeted responses to data queries and needs, reducing the time from question to insight.
And just as we started, we solve another increment of the problem, which reveals the next.
Now that we can analyse the data, we need the data. But, it turns out the data we have is dirty, and we are missing some outright.
So let's solve the next problem: Data sources and quality.
The Advent of Data Mesh: Solving the data source problem
Wow, well we went quite a way to get here, and a decade after talking about democratization, we are starting to recognize that governance is an activity, not a process. And democracy is more work than we originally thought.
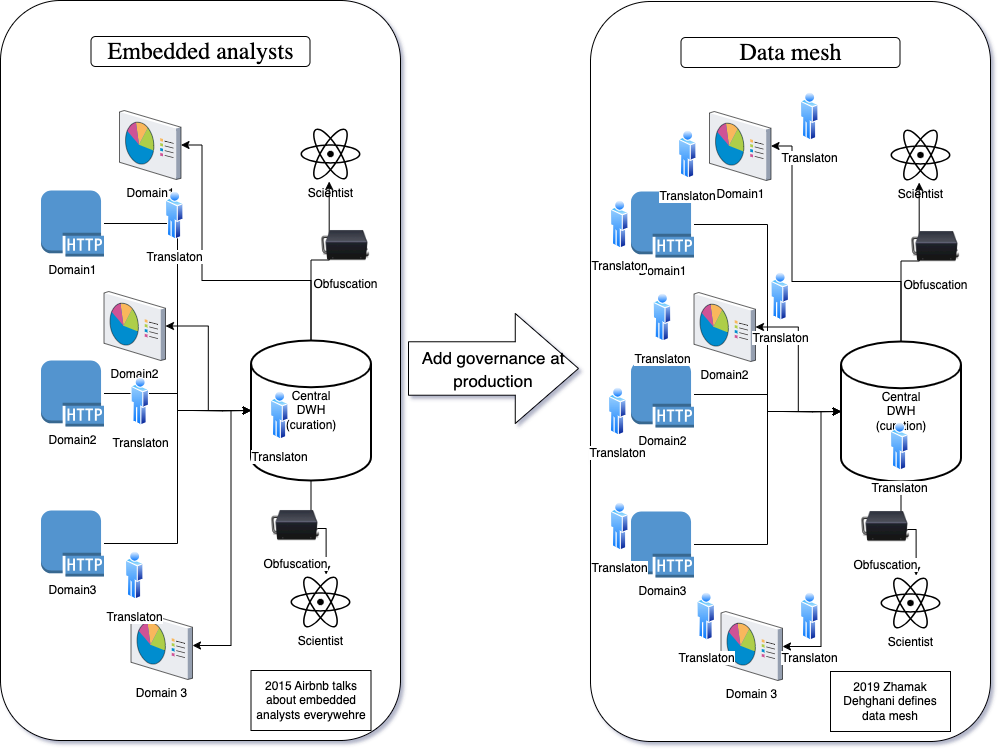
The data mesh architecture marks a significant evolution in the data democratization journey. Data mesh advances the principles of embedded analysts by decentralizing data ownership entirely, promoting domain-specific control over data assets.
This architectural approach is based on the idea that data should not only be accessible but also actionable across various sections of an organization without bottlenecks.
And just like governments hire a lot of people, turns out, a governance system also needs people to work for it.
Data mesh tries to solve much of that by embracing domain-oriented decentralization. In this model, data is treated as a product with the domain teams as the product owners. These teams are responsible for ensuring their data's quality and relevance, significantly reducing the latency issues found in centralized systems by eliminating the lengthy processes of data cleansing and approval.
Further, data mesh empowers teams with the necessary tools and authority to manage their data effectively, fostering a culture where data is a valuable asset across all levels of the organization. This approach not only supports rapid decision-making and innovation within teams but also offers scalability and flexibility as organizational data needs evolve, allowing domains to independently expand their data operations without a comprehensive overhaul of the central data infrastructure.
Of course, at this point having a complete or partial data platform that offers some governance starts to become very important as we don't want individual business units to be burdened with responsibity but without proper tooling - or the outcome will be high entropy.
From retrofitting governance to applying it from the start: Shift left data democracy!
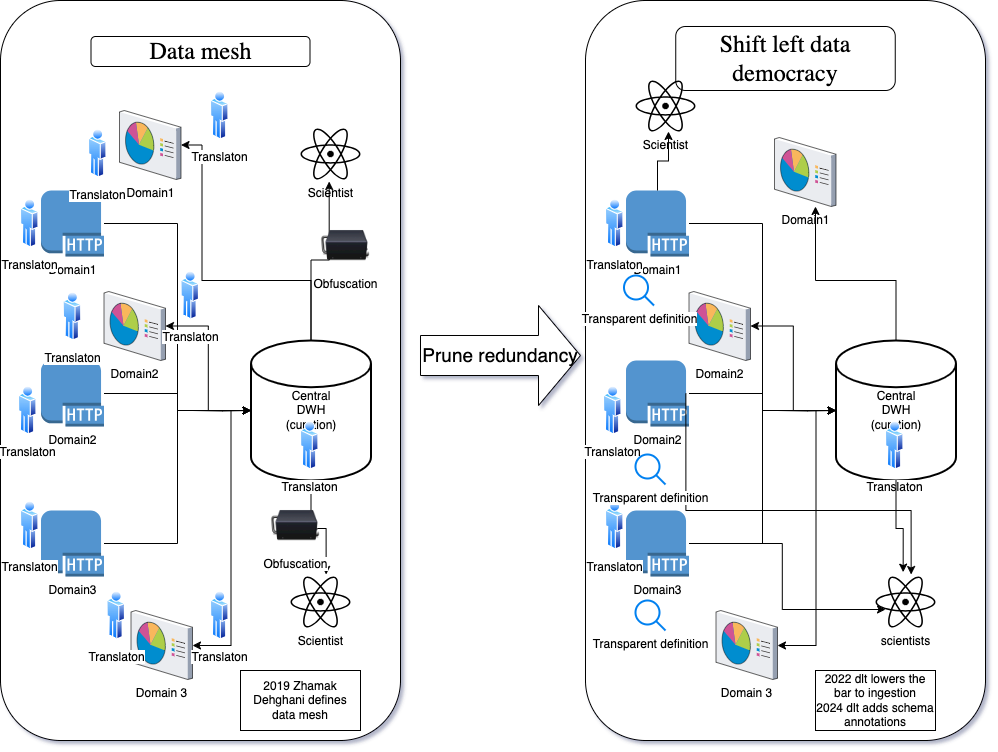
Imagine a world where your company's data sources can just be picked and unpacked in the destination of your choice by analysts - not through an external saas tool, but via an internal service portal.
Shift-Left Data Democracy (SLDD) is a concept in data management that advocates for integrating data governance early in the data lifecycle. This approach shifts governance practices from being a retrospective or reactionary activity to an integral part of the initial design and development phases of data systems. By doing so, SLDD aims to embed governance, quality controls, and compliance measures at the point of data creation and throughout its subsequent handling.
By embedding governance early in the data lifecycle, SLDD eliminates the complex and costly process of retrofitting governance frameworks to mature datasets and systems. This proactive approach leads to streamlined operations, reducing both the complexity and the cost traditionally associated with late-stage governance implementation.
This early incorporation of governance enhances transparency throughout the entire process. Stakeholders gain a clear understanding of how data is managed and governed from the start, building trust and ensuring compliance.
What's revolutionary about SLDD is that a governed data source can easily be unfolded into a normalised or analytical model.
This "ad hoc data mart" can be used without central bottlenecks and easily customised to fit specific cases without having to reach modelling consensus with other teams. This built-in modularity avoids the creation of more bottlenecks downstream, enabling fast research and development where needed.
Further, a well-defined governance framework enables greater innovation within safe boundaries. Teams can explore and innovate knowing they are aligned with compliance and operational standards, which speeds up experimentation and development cycles. This environment encourages a more dynamic approach to data handling, where creativity is not stifled by fear of violating governance protocols. By treating governance as an integral part of the data management process rather than a hindrance, SLDD fosters a culture where data truly drives innovation.
Distinction between data mesh and shift-left data democracy
While both concepts advocate for decentralized governance, they focus on different aspects of the data lifecycle. Data mesh architecture emphasizes the structural and operational decentralization of data management, granting autonomy to domain-specific teams. Shift-left data democracy, on the other hand, extends this decentralization to the very beginning of the data lifecycle, advocating for early involvement and broad stakeholder participation in governance processes.
The main difference is: Mesh is applied post-factum. For newly built systems, starting with governance as a technical universal standard is less complex. And while mesh grants autonomy, the entropy raises complexities and cost; on the other hand formalising and standardising responsibilities from the start of data production reduces entropy.
Practicing shift-left data democracy
So how do we do it? Is this a future or can we already do it?
We asked ourselves the same and we are working towards fully supporting the standard.
Ensuring quality at the source
Start with having quality control embedded in the source. Here's what I mean - start with a clear schema for your data, and ensure you have a strategy to adapt to change. One such strategy could be having data contracts, refusing and data that does not fit the defined schema. The other strategy, would be evolving the schema into a staging layer and notifying changes, so the engineering analyst can look into the data to understand what happened and correctly deal with the change.
At dlt we support schema evolution and data contracts. docs.
Metadata for full lineage
Column and row level lineage are a basic necessity of development and traceability, so ensure each ingested package is annotated with source and time. Keep track of when
columns are added to a source. Associate those schema changes with the corresponding load package to achieve column and row level lineage already from the ingestion layer,
referring to a source defined as pipeline code, not table.
Besides data lineage, you want semantic metadata. What does a source actually represent as a business entity or process? To govern data semantically, we would need semantic tags at the source. This would enable us to know how to work with the data. For example, we could generate data vault, 3nf, star schema or activity schema models algorithmically starting from annotated json documents.
Besides business entities, domains or processes, semantic tags could also designate PII, security policies, or anything actionable. For example, PII tags could enable automatic lineage documentation and governance, while access tags could enable automatic access policies or automatic data modelling.
dlt currently supports column and row level lineage, as well as schema comments - which could be used as annotations.
The role of the Data platform engineer will grow
In a shift left data democracy, the data platform engineer is a key character, as much as a CTO is in an organisation. By having a data platform engineer you ensure your data governance is done with automated tooling, to support implementation and compliance.
These data platform engineer becomes pivotal in empowering the democratization of data, providing the essential tooling and infrastructure that allow teams across the organization to manage their data autonomously.
Data platform engineers become enablers and facilitators, embedding governance and quality controls right from the start of the data lifecycle. Their work supports the organization by ensuring that data management practices are not only compliant and secure but also accessible and intuitive for non-specialists (democratic). This shift underlines a transition from centralized control to distributed empowerment, where data platform engineers support the broader goal of making data accessible, manageable, and governable across the entire spectrum of the organization.
The future of data management
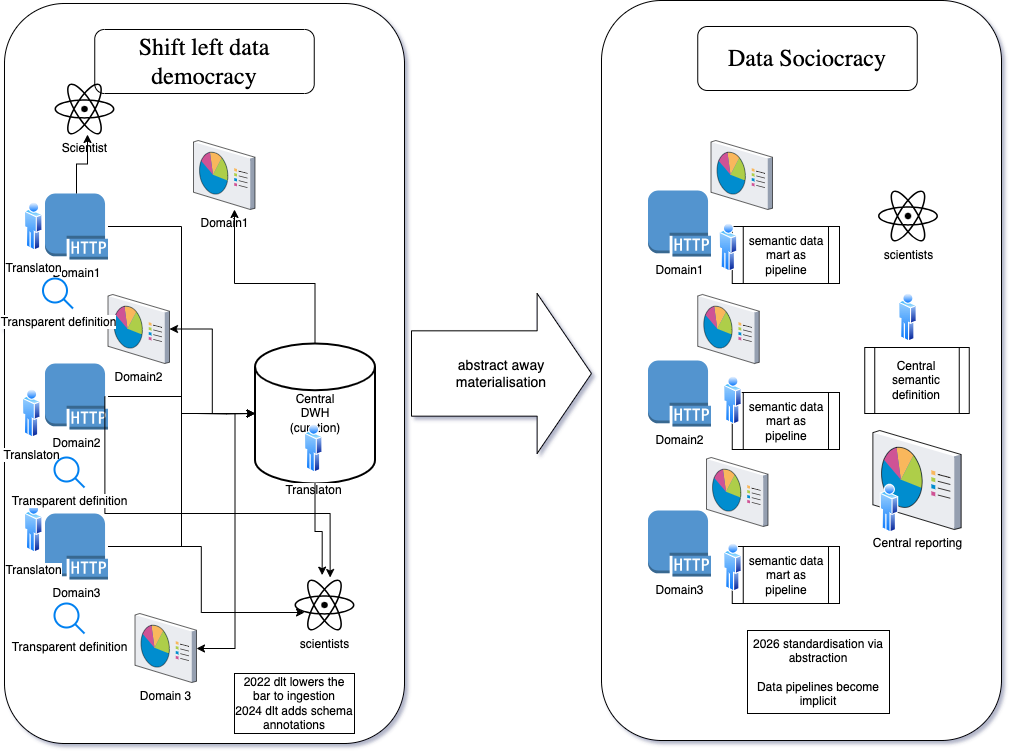
Are we heading towards semantically annotated data marts as code? Why not? We're in the age of serverless infrastructures, after all. Could data sociocracy become the future? Would we eventually encourage the entire organisation to annotate data sources with their learnings? Only time will tell.
Want to discuss?
Join the dlt slack community to take part in the conversation.