Dear dltHub Community,
We are thrilled to announce the launch of our groundbreaking pipeline generator tool.
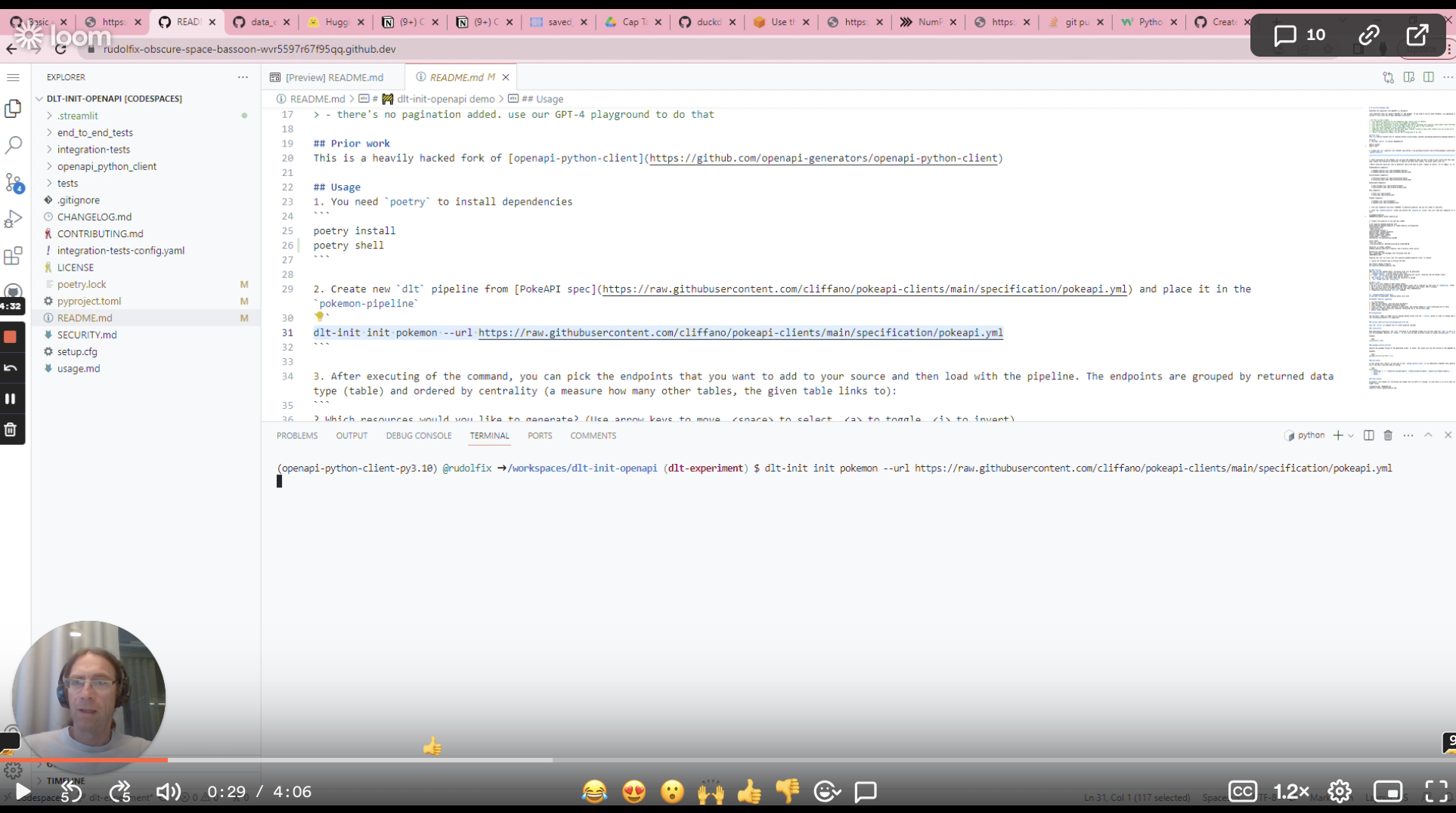
We call it dlt-init-openapi.
Just point it to an OpenAPI spec, select your endpoints, and you're done!
What's OpenAPI again?
OpenAPI is the world's most widely used API description standard. You may have heard about swagger docs? those are docs generated from the spec. In 2021 an information-security company named Assetnote scanned the web and unearthed 200,000 public OpenAPI files. Modern API frameworks like FastAPI generate such specifications automatically.
How does it work?
A pipeline is a series of datapoints or decisions about how to extract and load the data, expressed as code or config. I say decisions because building a pipeline can be boiled down to inspecting a documentation or response and deciding how to write the code.
Our tool does its best to pick out the necessary details and detect the rest to generate the complete pipeline for you.
The information required for taking those decisions comes from:
- The OpenAPI Spec (endpoints, auth)
- The dlt REST API Source which attempts to detect pagination
- The dlt init OpenAPI generator which attempts to detect incremental logic and dependent requests.
How well does it work?
This is something we are also learning about. We did an internal hackathon where we each built a few pipelines with this generator. In our experiments with APIs for which we had credentials, it worked pretty well.
However, we cannot undertake a big detour from our work to manually test each possible pipeline, so your feedback will be invaluable. So please, if you try it, let us know how well it worked - and ideally, add the spec you used to our repository.
What to do if it doesn't work?
Once a pipeline is created, it is a fully configurable instance of the REST API Source. So if anything did not go smoothly, you can make the final tweaks. You can learn how to adjust the generated pipeline by reading our REST API Source documentation.
Are we using LLMS under the hood?
No. This is a potential future enhancement, so maybe later.
The pipelines are generated algorithmically with deterministic outcomes. This way, we have more control over the quality of the decisions.
If we took an LLM-first approach, the errors would compound and put the burden back on the data person.
We are however considering using LLM-assists for the things that the algorithmic approach can't detect. Another avenue could be generating the OpenAPI spec from website docs. So we are eager to get feedback from you on what works and what needs work, enabling us to improve it.
Try it out now!
Video Walkthrough:
Colab demo - Load data from Stripe API to DuckDB using dlt and OpenAPI
Docs for dlt-init-openapi
dlt init openapi code repo.
Specs repository you can generate from.
Showcase your pipeline in the community sources **here
Next steps: Feedback, discussion and sharing.
Solving data engineering headaches in the open source is a team sport. We got this far with your feedback and help (especially on REST API source), and are counting on your continuous usage and engagement to steer our pushing of what's possible into uncharted, but needed directions.
So here's our call to action:
- We're excited to see how you will use our new pipeline generator and we are eager for your feedback. Join our community and let us know how we can improve dlt-init-openapi
- Got an OpenAPI spec? Add it to our specs repository so others may use it. If the spec doesn't work, please note that in the PR and we will use it for R&D.
Thank you for being part of our community and for building the future of ETL together!
- dltHub Team